
[Paper-ASR][中文笔记] 用于语音识别的无监督字符级分布适配 (CMatch)
Published:
Last Updated: 2021-07-04
这篇论文是我(Wenxin Hou)在MSRA实习期间与王晋东老师合作的工作,本文转载自王晋东老师的知乎:https://zhuanlan.zhihu.com/p/370691801。转载请联系王晋东老师或者我。
本期我们将为大家介绍一种用于语音识别的无监督字符级领域适配方法:CMatch。在这项工作中,我们提出一种用于ASR的无监督字符级分布匹配方法:CMatch,以实现在两个不同领域中的每个字符之间执行细粒度的自适应。在Libri-Adapt数据集上进行的实验表明,CMatch在跨设备和跨环境的适配上相对单词错误率(WER)分别降低了14.39%和16.50%。在这篇工作中我们还全面分析了帧级标签分配和基于Transformer的领域适配的不同策略。文章已经提交至INTERSPEECH 2021。
-
本文作者:侯汶昕(东京工业大学硕士生)

背景介绍
众所周知,基于深度学习的端到端自动语音识别(ASR)已经可以通过大规模的训练数据和强大的模型得到很好的性能。但是,训练和测试数据之间可能会由于录音设备,环境的不同而有着相似却不匹配的分布,这样的分布(或领域)不匹配通常会导致ASR模型在测试时的识别精度下降。而这种领域或分布不匹配的情况过于常见和多样,以至于很难对于每个领域的语音数据进行大量收集并标记。在这种情况下我们往往需要借助无监督的领域适配提升在模型目标域的表现。
现有的无监督领域适配方法通常在将每个领域视为一个分布,然后进行领域适配,例如领域对抗训练或是特征匹配。 这些方法可能就会导致忽略了一些不同领域内更细粒度的分布知识,例如字符,音素或单词。忽略这些信息可能会在一定程度上影响适配的效果。这在文献[1]中也得到了验证,与在整个域中对齐的传统方法相比,在子域中对齐的图像(即按类标签划分的域)通常可以实现更好的自适应性能。
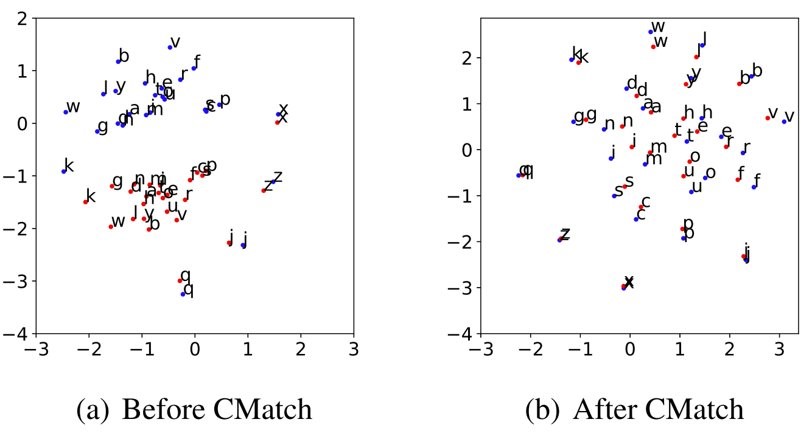
以下图为例,通过执行CMatch算法,我们可以看到两个领域相同的字符在特征分布中被拉近了。
方法介绍
CMatch由两个步骤组成:
- 帧级标签分配
- 字符级别的分布匹配
帧级标签分配
要想进行帧级标签分配,首先我们需要获得较为准确的标签对齐。这里我们介绍了如下图所示的3种方法:CTC强制对齐,动态帧平均,以及伪CTC标签方法。可以看出,CTC强制对齐是通过预训练的CTC模块,在计算每条文本对应的最可能的CTC路径(插入重复和Blank符号)后分配到每个语音帧上,这个方法相对准确但是计算代价较高;动态帧平均则是将语音帧平均的分配到每个字符上,这个方法需要基于源域和目标域语速均匀的假设;而伪CTC标签的方法,通过利用已经在源域上学习得较好的CTC模块外加基于置信度的过滤(如图中的t,e,p等),兼顾了高效和准确性。
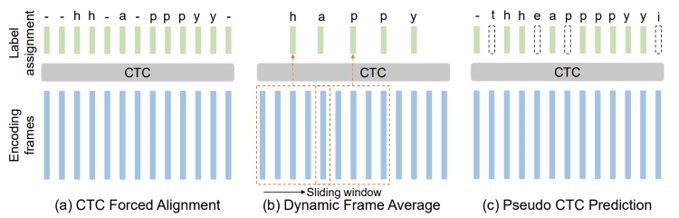
需要说明的是,我们在源域上使用真实文本进行标签分配,而由于目标域我们没有文本,所以需要借助源域模型首先在目标域的语音数据进行伪标注,然后使用模型标注的文本进行标签分配。
字符级别的分布匹配
得到帧级别的标签后,我们就需要进行字符级别的分布匹配,在本文中,我们选择采用Maximum Mean Discrepancy(MMD)度量进行特征匹配。MMD用于评估两个分布之间的差异,是迁移学习中常见的一种分布度量方法。它的公式为:
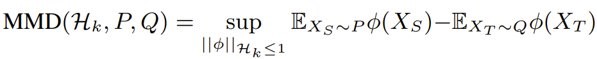
实际操作中,给定源域和目标域样本$X_S$, $X_T$,我们计算MMD的有偏差的经验估计:
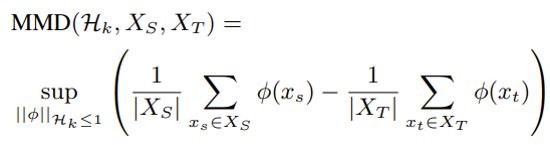
通过计算所有字符之间的平均MMD,我们可以得到字符级别的分布匹配损失函数:

最终损失函数和算法流程
本文中我们采取CTC-Attention混合模型作为基础ASR模型,以同时混合学习CTC模块(用于帧级标签分配)和基于Transformer Decoder的Seq2Seq Loss,于是语音识别的损失函数可以表示为:
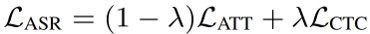
将分布匹配损失函数和语音识别损失函数相结合,我们就得到了最终的损失函数:
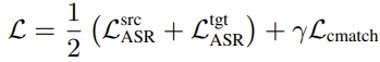
最终算法流程如下:

实验效果
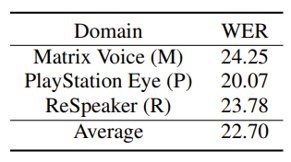
首先我们看一下模型在领域内的识别效果,评价指标为词错误率(WER),数值越低代表识别效果越好:
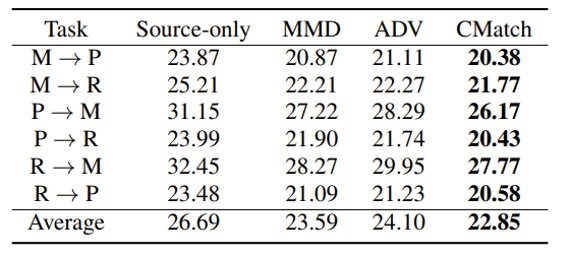
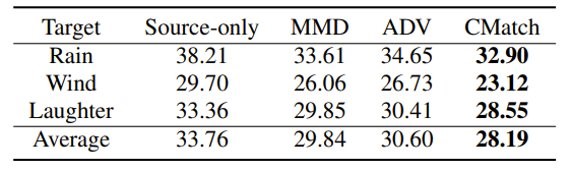
然后我们看一下跨设备语音识别时的结果,可以注意到的是,Source-only的模型在其他设备录制的语音上的识别效果相比领域内模型都会有一定程度的下降。而基于全局MMD和领域对抗训练的方法均有所提升,CMatch则在各个情况下均取得了最佳的效果。
可以看到,CMatch在跨环境(抗噪声)语音识别的情况下也取得了很好的效果。
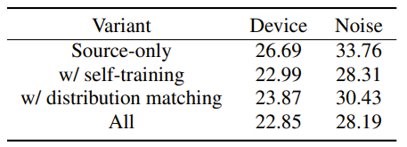
消融实验体现出,结合自训练和细粒度的分布匹配能够使CMatch达到最好的效果。
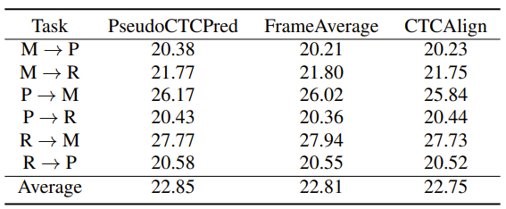
我们还分析比较了三种字符分配方法,可以看出CTC强制对齐取得了最好的效果,但是其计算开销也是最大;而FrameAverage也取得了较好的效果,但它的假设前提是领域和目标域具有均匀的说话速度;而使用CTC伪标签的方法取得了与CTC强制对齐相近的结果,同时计算起来也更加的高效。
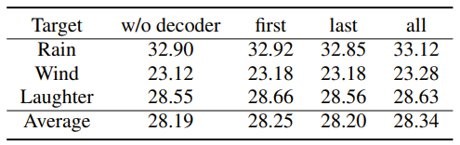
最后,我们分析了是否需要在解码器端也使用CMatch Loss,结果发现,由于解码器在我们的实验中本来就没有功能上的差别,目标文本都是标准的英文,因此减小其分布的差异并没有什么效果,甚至会损害性能。
总结
本文提出了一种用于跨领域语音识别的CMatch算法。我们的主要动机是匹配来自源域和目标域的字符级分布,以利用细粒度的字符信息进行更好的自适应,并且在跨设备和跨环境ASR上的实验表明了CMatch的优越性。在未来,我们计划在更多的任务和场景下进行实验,例如数据集自适应和说话人自适应。
References
[1] Y. Zhu, F. Zhuang, J. Wang, G. Ke, J. Chen, J. Bian, H. Xiong, and Q. He, “Deep subdomain adaptation network for image classification,” IEEE transactions on neural networks and learning systems, 2020.