
[Paper-ASR][中文笔记] A Comparative Study on Neural Architectures and Training Methods for Japanese Speech Recognition
Published:
Last Updated: 2021-07-04
本篇为原创文章,转载请联系我,谢谢!
本期我们将为大家介绍Google团队在 InterSpeech 2021 的一篇日语端到端(E2E)语音识别的工作,文中调研了各种最新的E2E建模技巧,诸如:LSTM / Conformer 作为encoder,CTC / Transducer / Attention-based Decoder;本文也验证了一些最新的训练技术,如SpecAugment,Variational Noise Injection (VNI) 和 Exponential Moving Average (EMA)。本文最好的模型 + 训练配置在CSJ eval1, eval2, eval3上分别达到了SOTA的4.1%, 3.2%, and 3.5%的字错误率(CER)。

背景介绍
由于日语里没有像英语那样明确的词分隔(空格),所以传统的HMM模型和发音词典都需要用一个分词器将日语文本切成词;而E2E模型可以直接对字(character)建模,极大简化了ASR模型的构建流程。
对于Encoder而言,带卷积的BLSTM第一次在日语语音识别超过了HMM模型,Transformer模型又超过了BLSTM模型,之后的Conformer模型进一步降低了在日语和其他语言上的CER。
对于Decoder而言,CTC 和 Attention 在之前的工作中用的比较多,但Transducer并没有在日语ASR中得到广泛的应用。Transducer和CTC一样很适合流式应用,并且它也能像Attention一样学习到输出之间的依赖关系。
训练技巧对于E2E模型也很关键,比如SpecAugment,VNI 和 EMA 技术都已经被证明对于训练ASR模型有效,但是还没有工作对它们进行充分的对比实验。
本文的贡献就是充分的对于以上提到的模型架构和训练技巧以及他们的组合进行了对比实验,并且在CSJ数据集上进行了多维度的评价(CER,training throughput,收敛性和推理RTF)
神经网络架构
模型由Encoder和Decoder组成,输入为 log-mel filterbank 特征,输出是后验分布,训练目标是最大化正确目标序列的后验概率。
BLSTM Encoder
首先用堆叠卷积下采样输入特征,然后用堆叠的BLSTM层递归式的进行帧级别的处理。
缺点是难以并行化,无法充分使用 GPU / TPU 加速。
Conformer Encoder
Conformer Encoder和 BLSTM Encoder 的区别就是用 Conformer 模块代替了 BLSTM 层。Figure 1为Conformer模块的示意图。Conformer使用基于相对位置编码 (Relative Positional Encoding) 的多头注意力机制建模全局特征,对于长度为 T 的输入序列,多头自注意力的计算和内存复杂度都是 O(T^2)。
Figure 2 展开了 Figure 1 中的 Convolution Module,该模块用于建模局部特征。
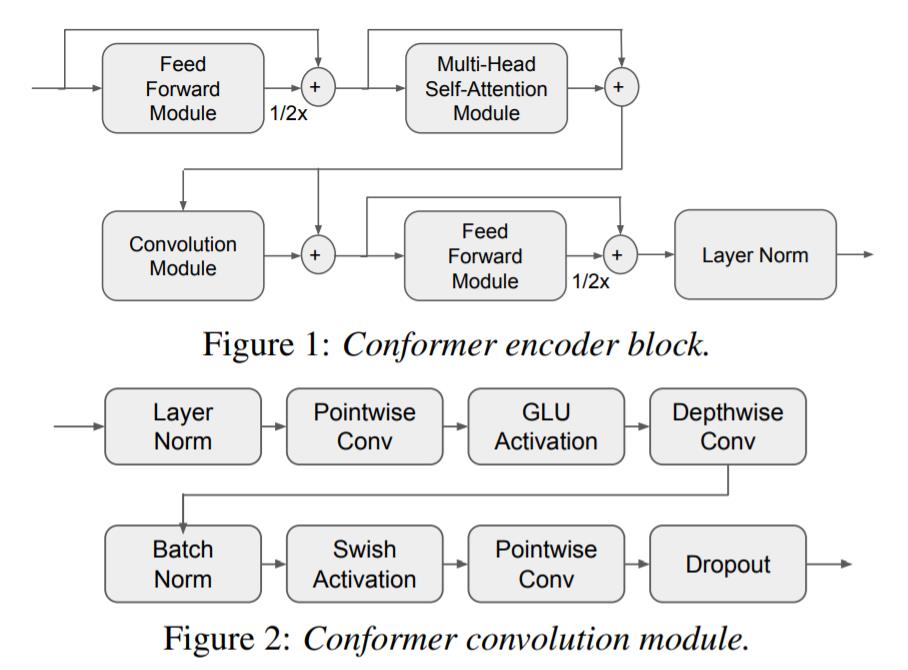
Conformer可以被并行化训练,因此相比 BLSTM 训练速度会快很多;但是缺点就是上述的注意力复杂度,当输入序列很长的时候可能会导致性能瓶颈。在本文实验中用 training throughput 评估。
CTC Decoder
CTC Decoder就是一层线性层 + Softmax 激活函数,CTC 通过引入一个表示 Encoder 编码的特征 X 和输出序列 Y 之间的 Alignment 的变量 Z 来预测输出序列的分布。Y 和 Z 之间的关系由一个多对一的映射 B 给出:
\[Y = B(Z)\]B(Z) 就是将 Z 中的 blank 和 重复 symbol 去掉,举个栗子:B(aa<blank>b) = ab。并且, Z 中的每一个 symbol $Z_t$ 被预测到的概率都是对应 X 中的一帧特征经过 CTC Decoder 转换预测得到的概率分布中的第 $Z_t$ 个元素,即$C_t=\text{CTC}(X_t)$ , $P(Z_t) = C_{t, Z_t}$ 。从这里我们也可以看出来,CTC进行了条件独立性假设,即 $Z_t$ 的预测与上下文 $Z_{t-1}$ 和 $Z_{t+1}$ 均无关。
那怎么训练 CTC 呢?我们对 B 取反得到一个一对多的映射 $B^{-1}$,比如 $B^{-1}(ab) = {\text{aa
Transducer Decoder
Transducer 和 CTC 原理类似,都是通过最大化可能的 Alignment 概率进行训练,区别在于 Transducer 去掉了CTC的条件独立性假设,而是递归地建模条件分布。
\[L_{\text{transducer}} = - log \sum_{Z \in B^{-1}(Y)} \prod_t p_\text{transducer} (Z_t | X, B(Z_{1:t-1}))\]Transducer Decoder 一般采用循环神经网络(RNN)进行递归式的编码。
Attention Decoder
Attention Decoder 一般由两个模块组成:注意力模块 Attend() 和 输出模块 Spell()。不像 CTC 和 Transducer,它不需要显式地对齐每一个语音帧和输出符号。
\[L_\text{att} = - log \prod_t p_\text{att} (Y_t | X, Y_{1:t-1})\]Attention Decoder 在 NLP 的各种序列生成任务(Seq2Seq)中有着广泛的运用,这里就不详细介绍了。
训练技巧
SpecAugment
SpecAugment 是一种为 ASR 设计的数据增强的方式。主要包含:time masking 和 frequency masking。(time warping没有在本文中使用)。对于这类 trick 而言,不说废话,上代码:
def spec_augmentation(x,
warp_for_time=False,
num_t_mask=2,
num_f_mask=2,
max_t=50,
max_f=10,
max_w=80):
""" Deep copy x and do spec augmentation then return it
Args:
x: input feature, T * F 2D
num_t_mask: number of time mask to apply
num_f_mask: number of freq mask to apply
max_t: max width of time mask
max_f: max width of freq mask
max_w: max width of time warp
Returns:
augmented feature
"""
y = np.copy(x)
max_frames = y.shape[0]
max_freq = y.shape[1]
# time warp
if warp_for_time and max_frames > max_w * 2:
center = random.randrange(max_w, max_frames - max_w)
warped = random.randrange(center - max_w, center + max_w) + 1
left = Image.fromarray(x[:center]).resize((max_freq, warped), BICUBIC)
right = Image.fromarray(x[center:]).resize(
(max_freq, max_frames - warped), BICUBIC)
y = np.concatenate((left, right), 0)
# time mask
for i in range(num_t_mask):
start = random.randint(0, max_frames - 1)
length = random.randint(1, max_t)
end = min(max_frames, start + length)
y[start:end, :] = 0
# freq mask
for i in range(num_f_mask):
start = random.randint(0, max_freq - 1)
length = random.randint(1, max_f)
end = min(max_freq, start + length)
y[:, start:end] = 0
return y
Exponential Moving Average (EMA)
EMA 通过维护一个影子权重来提高模型训练的稳定性和泛化能力,其基本假设是,模型权重在最后的n步内,会在实际的最优点处抖动,所以我们取最后n步的平均,能使得模型更加的鲁棒。每一个训练 step $k$ 后,EMA 的模型参数 $\theta_k’$ 通过下面的公式计算:
\[\theta_k' = \gamma \theta_{k-1}' + (1 - \gamma) \theta_k\]其中,$\gamma$ 是衰减率。代码如下:
class ExponentialMovingAverage(object):
def __init__(self, model, decay=0.9999):
self.model = model
self.decay = decay
self.shadow = {}
self.backup = {}
def load(self, ema_model):
for name, param in ema_model.named_parameters():
self.shadow[name] = param.data.clone()
def register(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.shadow[name] = param.data.clone()
def update(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
new_average = (1.0 - self.decay) * param.data + self.decay * self.shadow[name]
self.shadow[name] = new_average.clone()
# 以下函数用于评估模型时的参数变换
def apply_shadow(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
self.backup[name] = param.data
param.data = self.shadow[name]
def restore(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
Variational Noise
Variational Noise 也能提高神经网络的泛化能力,具体做法是对原参数加上服从正态分布的噪声样本,得到带噪参数用于训练。(本文只将其用于 embedding 和 LSTM 层)
\[\theta' = \theta + n, n \sim \text{Normal}(0, \sigma^2)\]这个方法比较简单并且灵活,这里就不放代码了。
实验结果
实验设置
简要介绍一下 CSJ 数据集:581 小时的语音数据,模型建模单元为3259个字 + 3种特殊字符 (SOS, EOS, UNK)。特征提取为 80 维的 log mel-filterbank,在训练集上采用了 Global CMVN (channel 轴上 0 均值,1 方差)。
各种超参就不介绍了,Google 使用的模型基本大家都可以想象一下,小不了。诸如 SpecAugment 等的参数可以参考一下原论文。
模型架构 对比
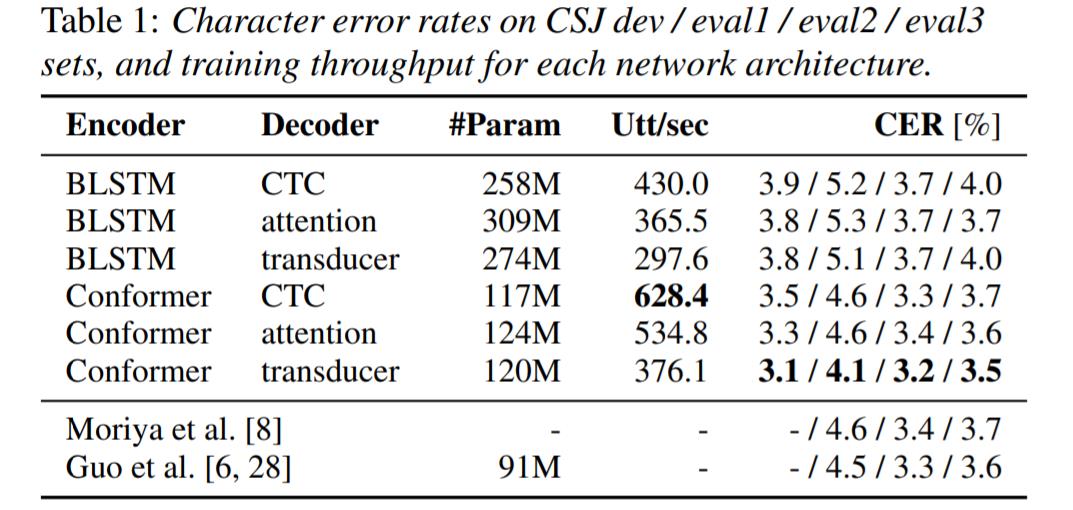
首先,由表 1 可以看出,Conformer 作为 encoder 明显好于 BLSTM,不论是 CER 还是训练速度 ;Decoder 方面,Attention 和 Transducer 整体表现接近,CTC 略差,从训练速度看是 CTC 大于 Attention 大于 Transducer。
Encoder 对于 CER 结果的影响明显大于 Decoder。
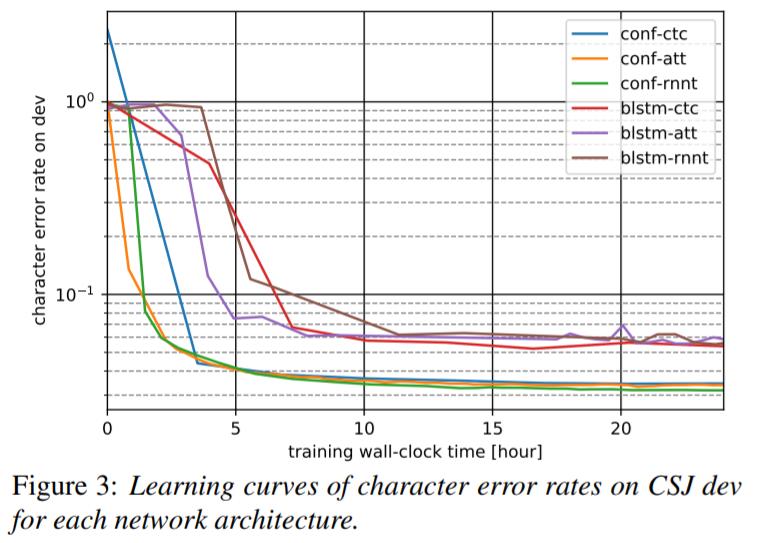
从收敛性的角度看,Conformer 的收敛速度和效果依然明显优于 BLSTM,Attention Decoder 则在训练早期有着更快的收敛速度,但是这个效果也不如 Encoder 部分来的明显,训练后期差距被拉小甚至反超。
训练技巧 对比
从 CER 的角度看,SpecAugment 带来的提升 大于 EMA 大于 VNI,但是他们是互补的,组合起来可以达到最佳的训练效果。
各种技巧对于训练速度几乎没有影响,可以放心食用。
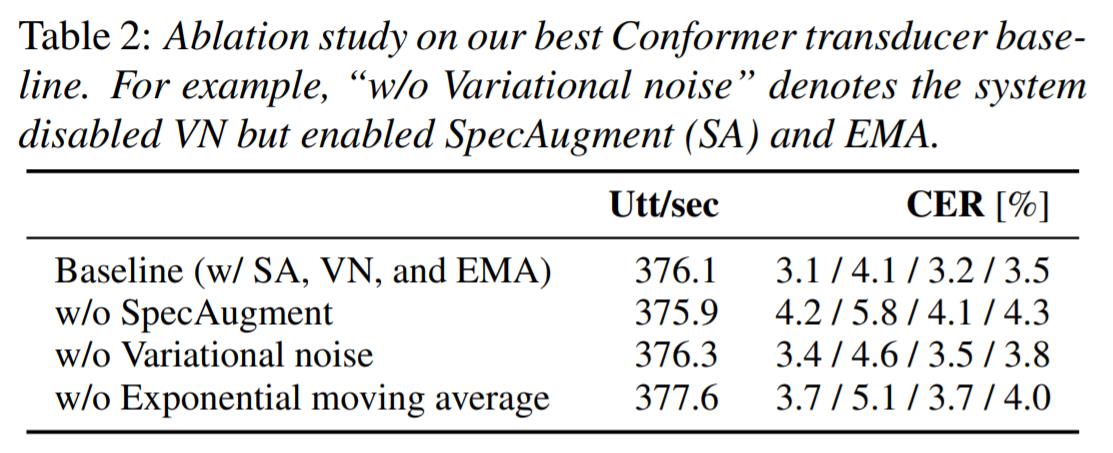
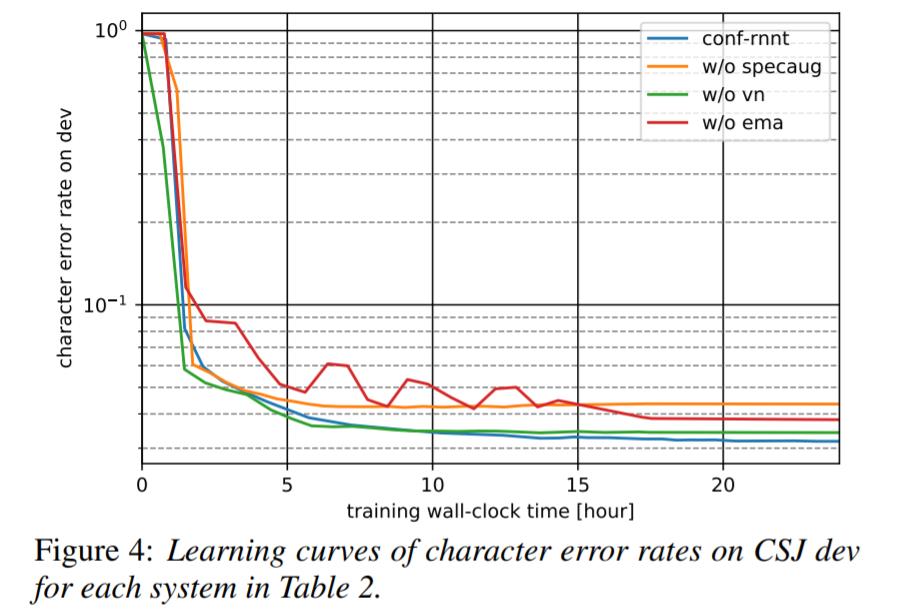
从收敛曲线看,没有 EMA 的模型训练(红色)明显变得不稳定,使用 EMA 可以帮助加速收敛。
计算复杂度 对比
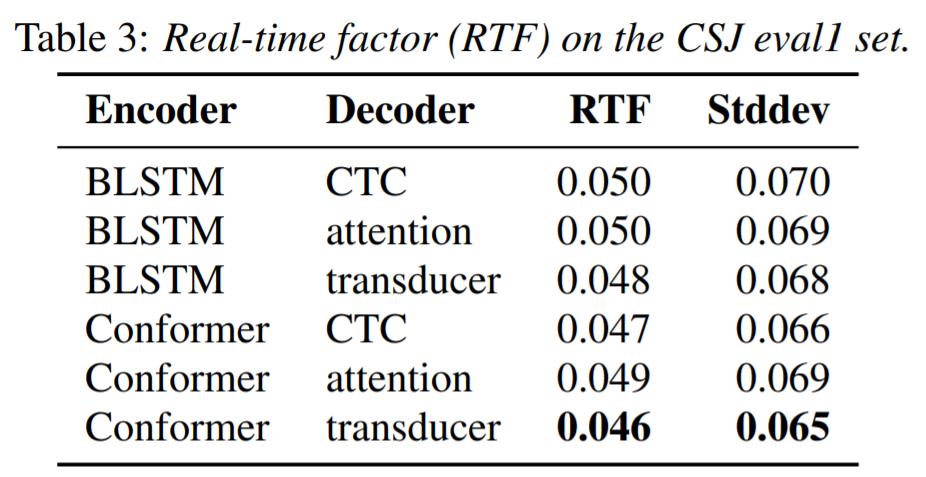
作者将 batch size 设置为 1,然后在 CPU 上解码,然后计算 Real-Time Factor (RTF),RTF 用于度量解码速度,计算方法为用模型解码一条语音的时间除以该条语音自身的时间,数字越小越好。
可以看出,Conformer 作为 Encoder 依然 优于 BLSTM,Transducer 作为 Decoder 是最快的,CTC 次之,Attention Decoder 最慢 。值得注意的是 Attention 和 Transducer 运用了宽度为 8 的 Beam Search 而 CTC 使用了 Greedy Search。不过本文的搜索算法都是用 C++ 写的,所以表上列出的算法其实都很快了。
总结
本文探究了各种模型架构、训练技巧在日语端到端语音识别上的应用,是一篇很棒的工程论文。